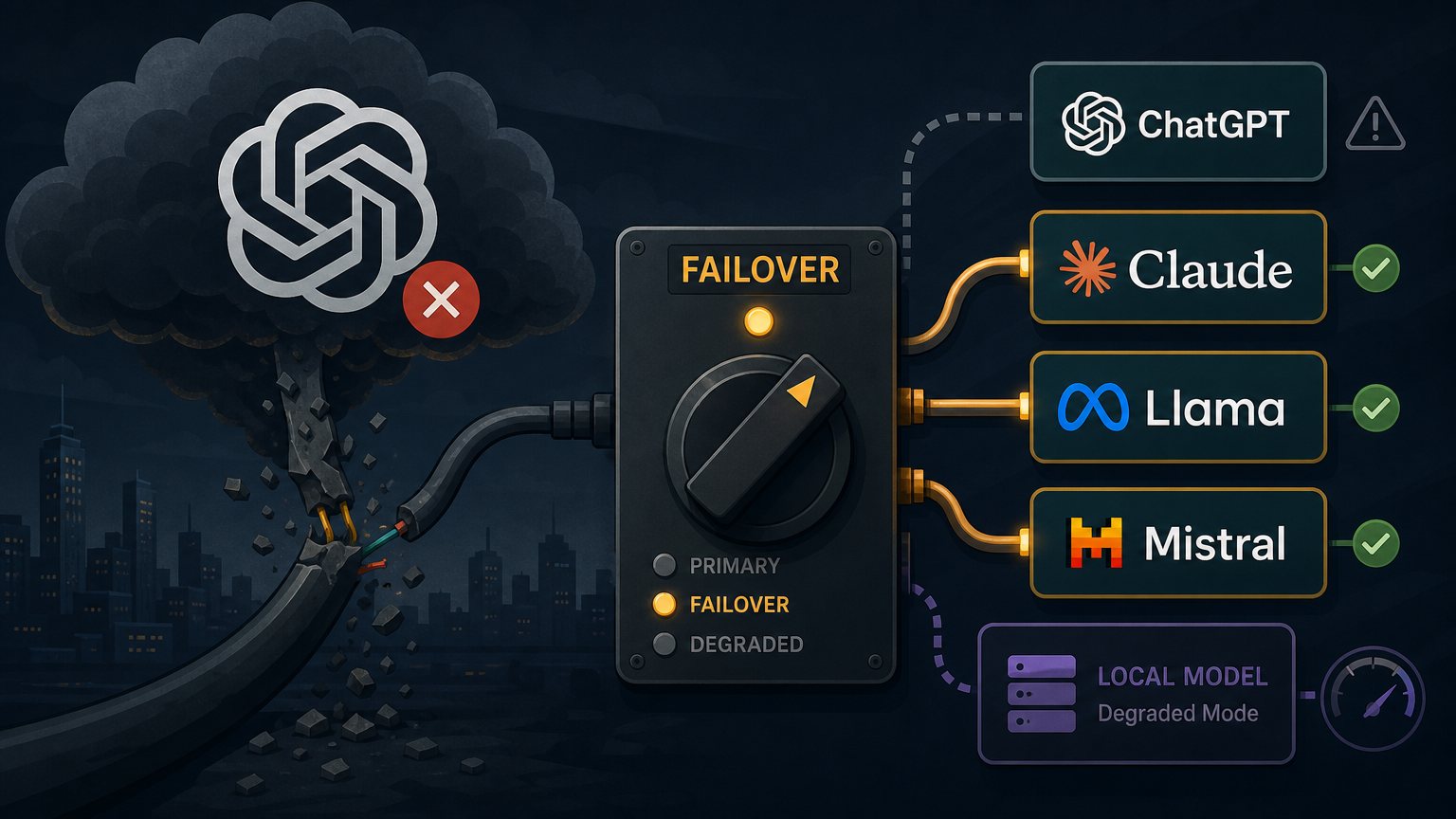
ChatGPT was having issues yesterday for me and my wife — and it got me thinking. We've spent two decades building redundancy into every other layer of the stack. Multi-region database replication. Cross-cloud object storage. BGP failover for connectivity. We treat a single point of failure like a fireable offense in production infrastructure. Yet somehow, an entire generation of business workflows — from customer support to code generation to internal knowledge bases — is now hard-wired to maybe three or four LLM providers, with zero failover strategy in place.
It's bad enough when Cloudflare or AWS us-east-1 has a bad afternoon. At least those outages have well-understood blast radius and well-documented mitigations. But when Claude or ChatGPT goes dark, there's no equivalent of "just flip DNS to the secondary." The prompts behave differently. The output formats drift. Function calling syntax varies. Even if you have an OpenRouter-style abstraction in front, your fine-tuned prompts and your evals are quietly coupled to one provider's quirks.
The "backup" isn't really a backup — it's a different product wearing the same shape. This is where I think DRaaS for LLMs becomes a real category, not a buzzword. The interesting questions aren't "should we self-host Llama 3.3 on a couple of H100s?" — they're architectural. How do you design a prompt and tool layer that's genuinely portable across providers? How do you keep a local model warm enough to serve degraded-mode traffic without burning capacity 24/7? What's the SLA tier where it's worth running your own inference? I'm curious what others are doing here. Are you building real failover, accepting the risk, or quietly hoping it doesn't happen on a Monday?